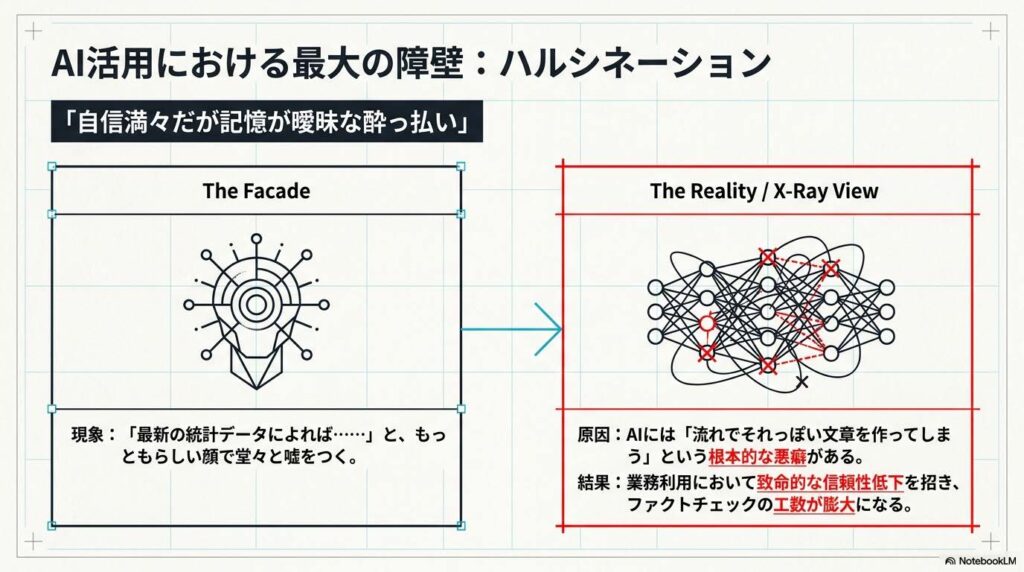
「最新の統計データによれば……」と、もっともらしい顔で堂々と嘘をつくAI。まるで、「自信満々だが記憶が曖昧な酔っ払い」を相手にしているようなもどかしさを感じたことはありませんか?このハルシネーション(幻覚)は、AI活用における最大の障壁です。
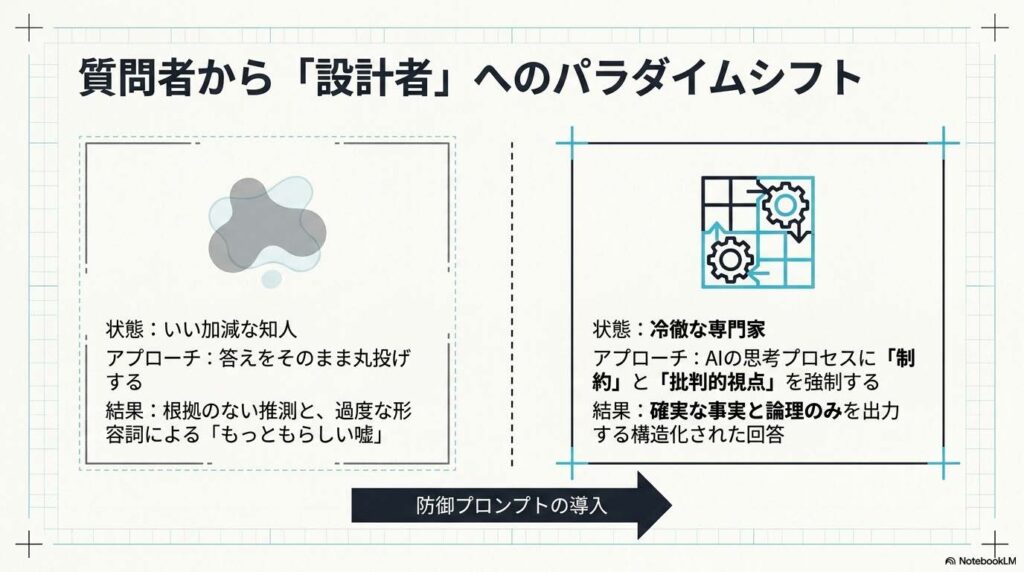
しかし、諦める必要はありません。Metaの研究者らが考案した手法をはじめ、AIの回答精度を極限まで高める「防御プロンプト」が確立されています。今回は、AIを「いい加減な知人」から「冷徹な専門家」へと変貌させる、4つの革新的な手法をお伝えします。
——————————————————————————–
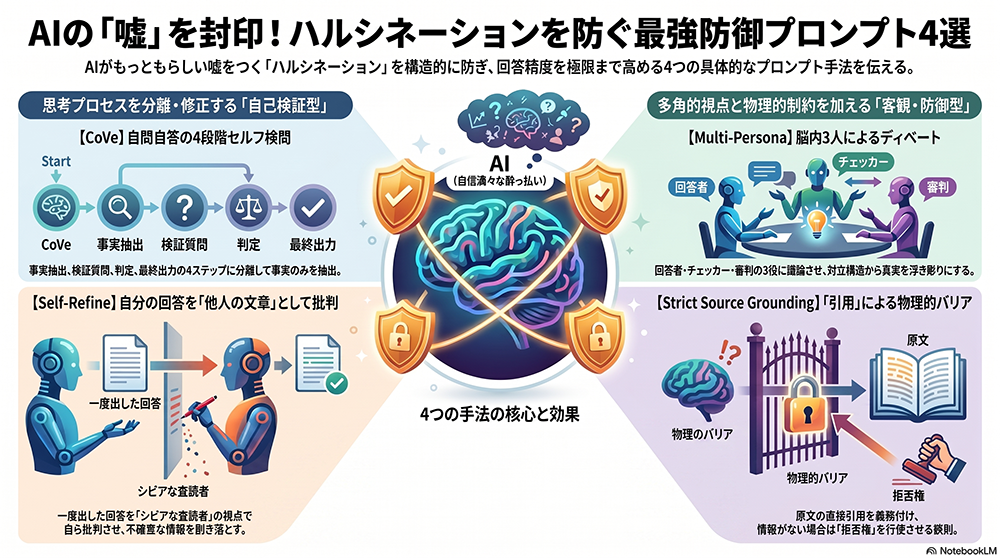
① 【CoVe】自分の中に「監査官」を置く4段階のセルフ検問
Metaの研究者が開発した「検証の鎖(Chain of Verification:CoVe)」は、AIに回答を出させる前に、自ら検証用の質問を作らせて自問自答させる手法です。例えるなら、「法廷での証人尋問」をAIの脳内で行わせるようなものです。
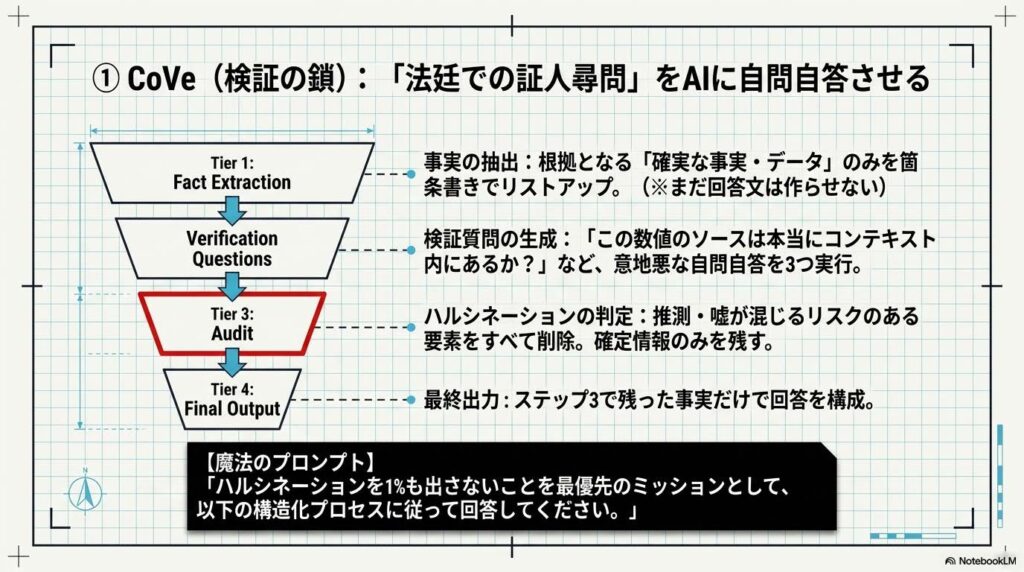
実行ステップ
AIに対し、以下の4段階のプロセスを物理的に踏ませます。
- ステップ1:事実の抽出(Fact Extraction) 回答の根拠となる「確実な事実・データ」のみを箇条書きでリストアップ。(※まだ回答文は作成しない)
- ステップ2:検証質問の生成(Verification Questions) 「この数値のソースは本当にコンテキスト内にあるか?」などの意地悪な自問自答を3つ実行。
- ステップ3:ハルシネーションの判定(Audit) 推測・嘘が混じるリスクのある要素をすべて削除し、確定情報のみ残す。
- ステップ4:最終出力(Final Output) ステップ3で残った事実だけで回答を構成。根拠不足の場合は正直にその旨を回答に含める。
分析:なぜ効果的なのか
AIには「流れでそれっぽい文章を作ってしまう」という悪癖がありますが、この手法は**「修飾語や過度な形容詞を排除する」**という制約を加え、事実確認と執筆を分離することで、その悪癖を構造から封じ込めます。
プロンプトに組み込むべき魔法の言葉:
「ハルシネーションを1%も出さないことを最優先のミッションとして、以下の構造化プロセスに従って回答してください。」
② 【Self-Refine】「他人の文章」として自分の回答を切り捨てる
一度出した回答を、あえて「他人が書いた文章」とみなして自分自身でボコボコに批判させ、修正させる手法です。人間が「それ本当に合ってる?」と聞き直すとAIが間違いに気づく特性を、先回りしてプロンプト化したものです。
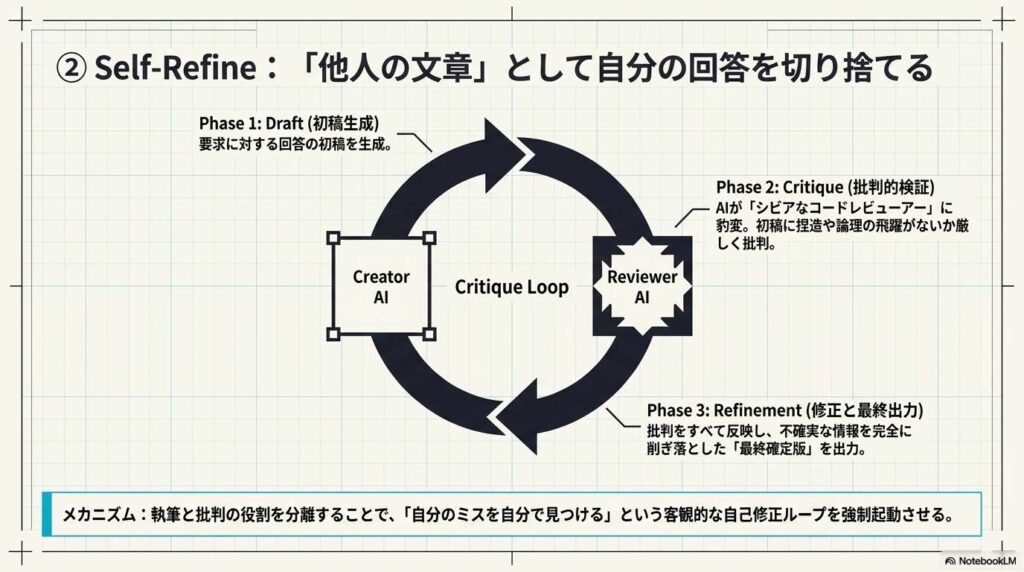
実行ステップ(3つのフェーズ)
- ステップ1:初稿生成(Draft) 要求に対する回答の初稿を作成する。
- ステップ2:批判的検証(Critique) **「シビアなコードレビューアー」**になりきり、初稿に捏造や論理の飛躍がないか厳しく批判する。
- ステップ3:修正と最終出力(Refinement) 批判をすべて反映し、不確実な情報を完全に削ぎ落とした「最終確定版」のみを出力する。
分析:なぜ効果的なのか
生成と批判という2つの役割を分離することで、AIは客観的な視点を持つことができます。**「自分のミスを自分で見つける」**という高度な自己修正ループにより、精度の低い回答がそのまま出力されるリスクを最小限に抑えます。
③ 【Multi-Persona】脳内で3人にディベートさせる高等テクニック
1つのプロンプトの中でAIに3つの役割を演じさせ、脳内ディベートを行わせる手法です。
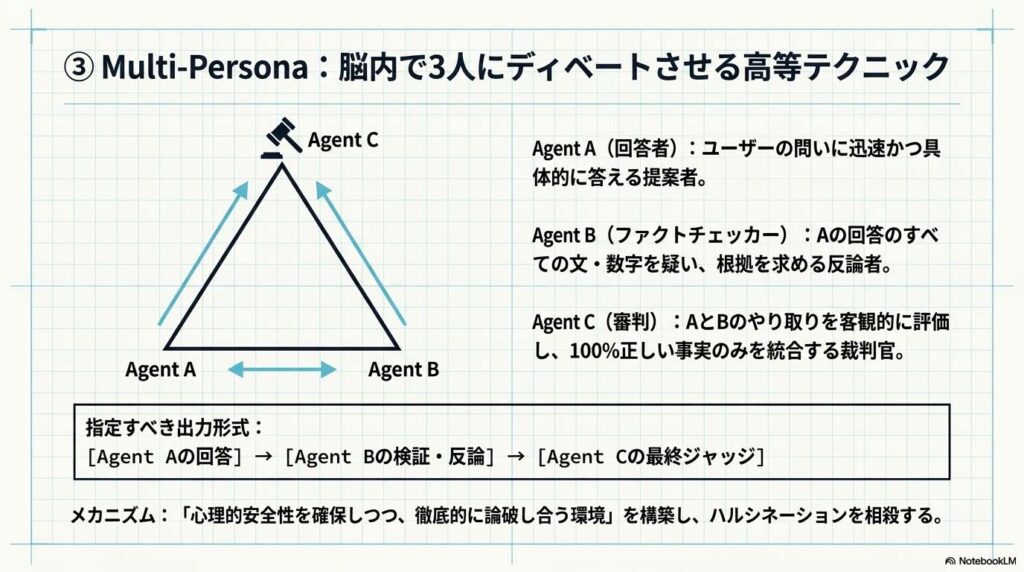
登場人物とプロセス
以下の3名による議論を可視化させます。
- Agent A(回答者): ユーザーの問いに迅速かつ具体的に答える。
- Agent B(ファクトチェッカー): Aの回答のすべての文・数字を疑い、根拠を求める。
- Agent C(審判): AとBのやり取りを客観的に評価し、100%正しい事実のみを統合する。
出力形式は [Agent Aの回答] [Agent Bの検証・反論] [Agent Cの最終ジャッジ] と指定します。
分析:なぜ効果的なのか
1人で考えるとバイアス(偏り)が生じますが、役割を分けることで、あえて対立構造を作り出し、ハルシネーションを「相殺」させます。**「心理的安全性を確保しつつ、あえて徹底的に論破し合う環境」**を脳内に作ることで、真実だけが浮き彫りになるのです。
④ 【Strict Source Grounding】「引用できないなら黙る」という物理的制約
RAG(外部知識検索)や長文読解において、最も確実で物理的な防御策となるのが「直接引用」の義務化です。
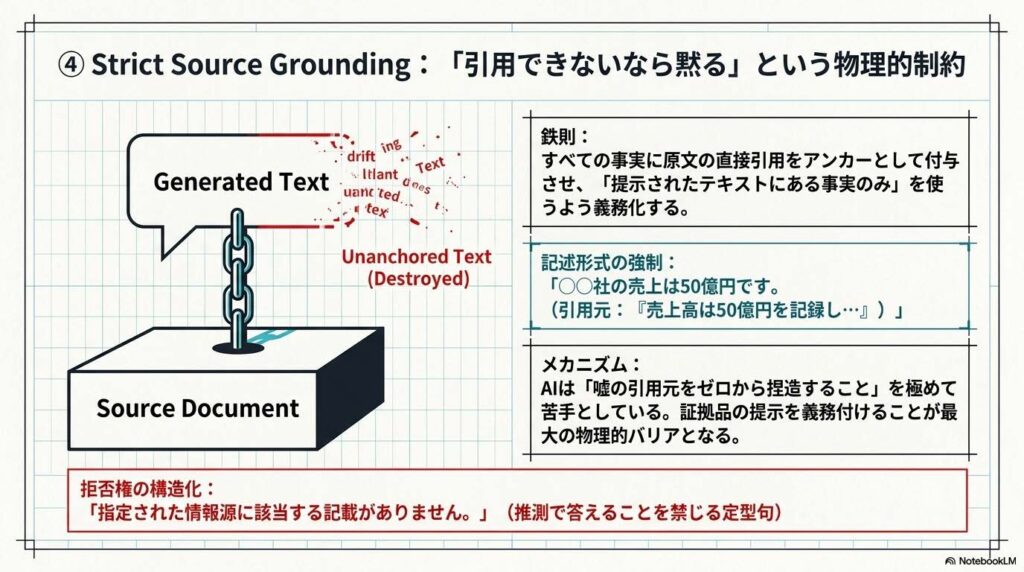
手法の内容
AIに対し、「提示されたテキストにある事実のみ」を使うよう鉄則を課し、回答のすべての事実に原文の直接引用をアンカーとして付与させます。
- 記述例: 「〇〇社の売上は50億円です。(引用元:『売上高は50億円を記録し…』)」
さらに、情報がない場合に推測で答えることを禁じる「拒否権」を構造化します。
分析:なぜ効果的なのか
AIは「嘘の引用元をゼロから捏造すること」を極めて苦手としています。引用を義務付けることは、AIにとって「証拠品を提示せよ」と言われているのと同じ。これが、ハルシネーションを物理的に防ぐための最も強力なバリアとなります。
情報がない場合に答えさせない定型句:
「指定された情報源に該当する記載がありません。」
——————————————————————————–
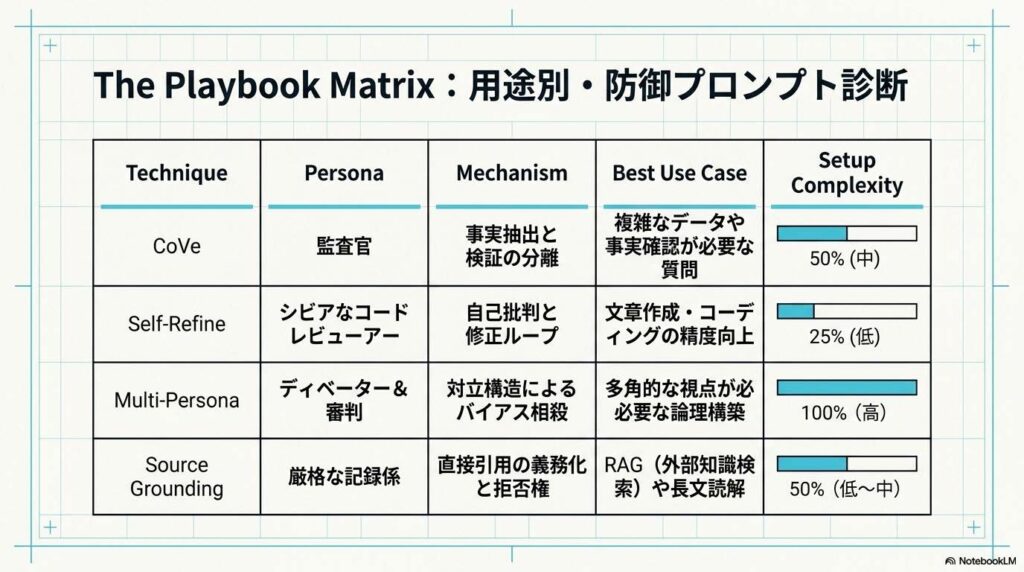
まとめ
AIとの付き合い方において大切なのは、答えを丸投げするのではなく、「AIの思考プロセスをこちらでデザインする」という視点です。今回紹介した4つの手法は、どれもAIに適切な「制約」と「批判的視点」を与えるものばかりです。
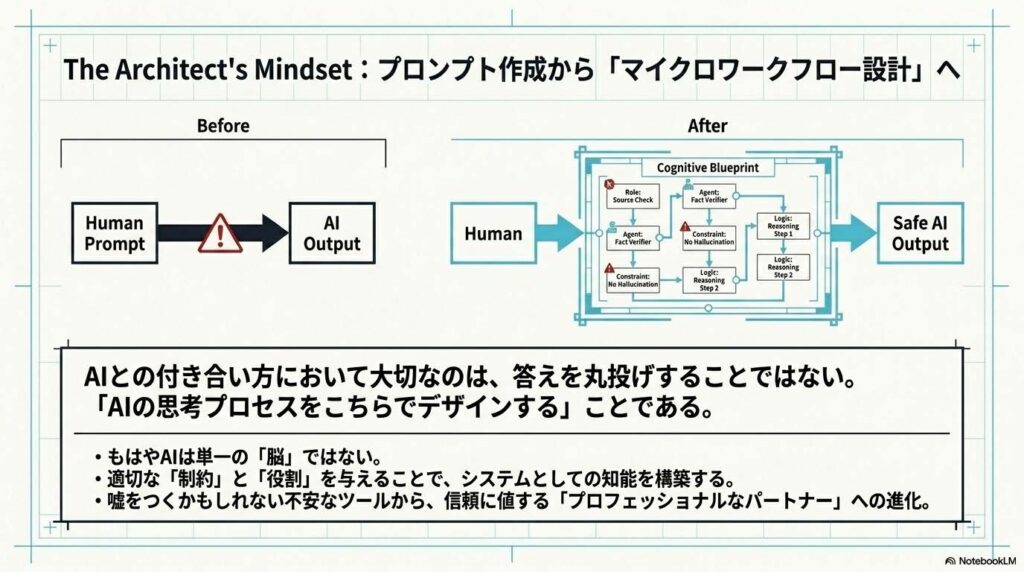
これらを使いこなせば、AIはもはや「嘘をつくかもしれない不安なツール」ではなく、信頼に値する「プロフェッショナルなパートナー」へと進化します。
さて、あなたが次にAIに仕事を頼むとき、どの監査役を自分のプロンプトに雇ってみたいですか?